“Hackathons are just about chaining API’s together.” As my project partner, Sam Maynard delivered this truth to me, I felt the magical hope I had towards life diminish slightly. What I thought were congregations to debut new technologies ended up just being competitions to see who could write some wrapper around already existing API’s provided by tech giants. I say some because I was unable to deduce what kind of metric was used to rank projects at the hackathon I went to. Not to mention, HackRice 7 was my very first hackathon, so this was all news to me. In any case, we didn’t let the harsh reality deter us, we set forth to coming up with an interesting project that would solve an interesting problem in an interesting way. After much discussion and staring at the prize page, we decided upon a project.
Predict exchange rates between cryptocurrencies in order to be prepared for when arbitrage occurs in the market.
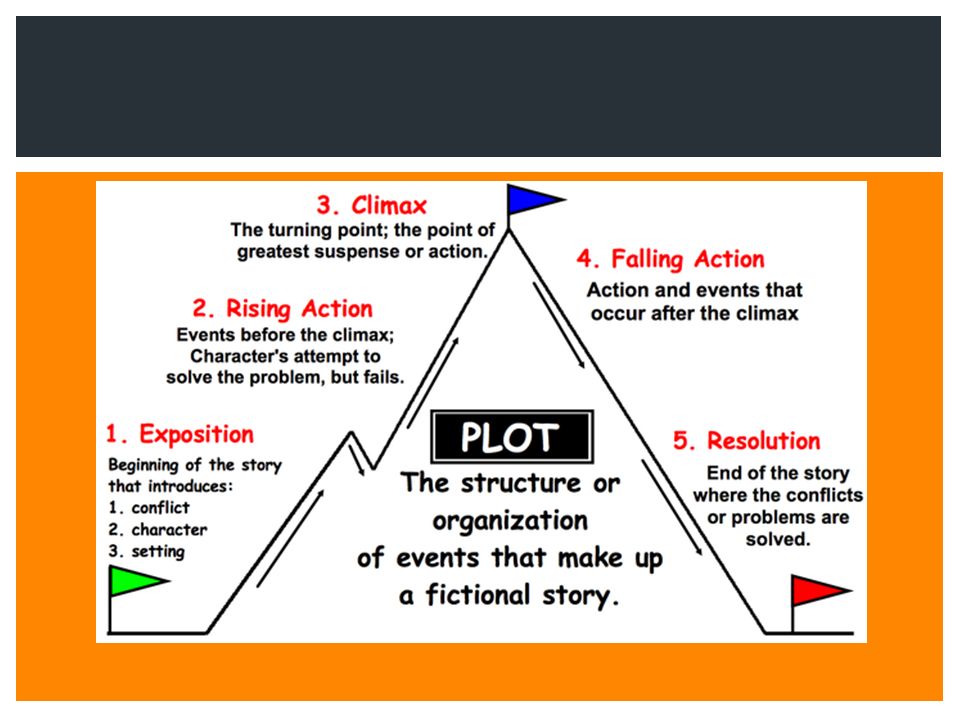
Conflict
Now, whether you are familiar with financial/cryptocurrency markets or not, I know exactly what you’re thinking. “Eric, ya dingus, there are definitely a million people who monitor arbitrage for cryptocurrencies. They are, for sure, faster than you and have more capital.” “Predicted values? Is this future arbitrage? Isn’t that just trading?” “Are you trying to model something similar to stock prices? People devote entire careers to this. You’re not going to crank anything interesting out.” First of all, reader, chill out. This is a hackathon project. Second of all, don’t worry, we thought of it too; I’ll address these points after some explanation.
There are some current problems people face when attempting to perform arbitrage in cryptocurrency markets. One, certain transactions take an hour to verify, which means it will be an hour before you get your capital back. In this time, exchange rates could easily change in such a way that a plan you had initially would be no longer profitable. Two, transaction fees can render potential profits to be losses. Three, within an exchange, there really shouldn’t exist any opportunities for arbitrage, but across exchanges, there might. However, following my first point, it takes time to move capital between exchanges. Given these three characteristics, it can be difficult for individual, small-scale investors, who don’t have enough liquidity in each currency, to be ready to take advantage of arbitrage were it to become available.
Rising Action
After much deliberation, Sam and I decided on our project pipeline. It would start with data collection. Then we would use the collected data, exchange rates in our case, to generate statistical models that would give us estimates for values in the near future. Finally, we would enter these predicted values into a custom graph search algorithm that would return a suggested sequence of actions to take in order to maximize profit.
To address the points above, we considered this “arbitrage” because it was technically as fast as a small investor could move money around, given the time constraints. Also, we weren’t particularly invested in the accuracy of the models, we simply needed some predicted values, good or bad, to show a proof of concept. Of course, more accurate models would lead to more accurate profits.
So we set to work. Sam worked on writing a program to periodically retrieve data from CoinMarketCap while I wrote the custom graph search algorithm. For simplicity, we decided to just consider the US dollar, Bitcoin, and Ethereum. We modeled the problem as such. Each exchange, Gemini, Bitfinex, etc., consisted of 3 nodes and 3 edges to form a triangle. Each node represented a currency and each edge the exchange rate within the exchange. So within this graph, we would need to find a sequence of actions that would result in the maximum ending capital. The reason we needed our own graph search algorithm is because the edges “changed values” over time, we needed to find the maximum value path, and there are multiple goal states (we considered a goal state to be any node that matched the starting currency type, regardless of the exchange). Finally, to generate predicted values, we used fbprophet for its simplicity, although it really doesn’t seem to be built for stochastic processes, like stock prices.
To verify that our program’s suggestions actually turned a profit, we wrote a script that would feed a prefix of our collected data into the program, perform the suggested actions on real data, and then output the estimated and actual value.
Climax
Our program worked! Given $100, it would, on average, return a sequence of actions with an expected value of $105. Using our verification script, weirdly enough, actual profits were always under the expected values. For an expected value of $105, the actual profits would be around $102. This may have been due to the optimizer’s curse, but I am not sure. We were just happy it would return a profit. Most likely, with better statistical models, the actual value would be closer to the expected.
Falling Action
Well, we weren’t finalists. But we did win a company prize from the gracious HBK. It seemed like the people who were finalists had something to present, whether it be some graphs, slides, or even just a visual demo. I do concede, if we had to present, people would have just heard us drone on while watching nonsensical output scroll away on a terminal.
Resolution
Would I put my own money on this? Maybe. I feel like every part of the program is solid, except the prediction, which is extremely important. Maybe if I were able to provide some confidence intervals, I would have more faith in using this as an investment tool. All in all, it was a fun weekend, and a good first experience for hackathons. Check out Sam’s experience here.
I was watching This is the End with my friends the other day, and among the various goofs and gaffs, we witnessed the match scene.
Just to provide a little context of the scene I will be talking about, in case any traces of the scene was removed from all corners of the internet, a couple people are stuck in a house due to an apocalypse. They need water, but it’s in a basement that can only be accessed from the outside. To decide who goes, Seth Rogen lights a match and hides it with a bunch of other matches, and whoever pulls the burnt match has to risk his life to get some water.
As the scene was unfolding, I assumed that they would all pick a match at the same time and then reveal who picked the burnt match. Then, when Craig Robinson volunteers to go first, I had a little internal monologue. Is he dumb?Why would you volunteer to go first? Wouldn’t it be better to let others go first so they incur risk before you do? But after discussing with my friends for a bit, we concluded that he was a genius because going early is better than going last because you have a larger population of matches and thus a smaller chance of drawing the burnt match. As the movie progressed, my mind stayed behind. Maybe it doesn’t matter who goes first. Or maybe there is some optimal turn to go based on the number of matches. Anyway, let’s figure this out with basic math.
In this scenario, if Craig were to go first, he has a 1 in 7 chance of picking the burnt match. Now, say he decides to wait to be the third person to draw a match, if it gets to that. The probability of his drawing a match is 6/7 * 5/6 * 1/5. This even extends to the event of drawing a match as the second to last person: 6/7 * 5/6 * 4/5 * 3/4 * 2/3 * 1/2. The numerators and denominators nicely cancel out with neighboring terms, so that no matter which turn Craig waits until, the probability is 1/7. Just to be thorough, let’s take into account every possible outcome in the event that Craig decides to wait to be the third person. The probability that he draws the burnt match is 1/7, the probability that he doesn’t is 6/7 * 5/6 * 4/5 = 4/7, and the probability that someone before him draws the burnt match is 2/7, as each person before him also has a 1/7 chance of drawing the match. All of the probabilities nicely sum to 7/7.
In conclusion, yes, this is all very simple math. I wouldn’t be surprised if this is common knowledge in a field like game theory or combinatorics. This also explains why Craig was so quick to go first. He quickly crunched the numbers and realized it didn’t matter.
During college, I have developed a strong affinity for board games. My group of friends is not interested in sports, degenerate activities, or going outside in general, so board games served the purpose of setting a landscape for us to scheme and strategize against one another. My gateway board game was The Settlers of Catan. Unlike “lame” board games like Sorry, Battleship, Chutes and Ladders, and what I am probably incorrectly classifying as American board games, Catan showed me board games could be fun and not the alternative activity in the case of a power outage. Catan brought me into a world created by people with very European sounding names, such as Klaus Teuber (Catan) and Klaus-Jürgen Wrede (Carcassonne). However, I was eventually steered away from Catan due to, despite what Wikipedia says, how I perceived luck to play too big of a role in the outcome. I had to find something to fill the deep void that Catan left in my soul.
7 Wonders
Amidst my spiritual journey, I found 7 Wonders. It checked all the boxes; it was fast-paced, sufficiently complex (maybe even too complex), and most importantly, designed by some European guy, Antoine Bauza. For those who are new to 7 Wonders, its goal is just like that of any other board game, to maximize victory points, except there are 2100 different ways to do so.
Genetic Algorithm
In the face of 7 Wonders’ extreme complexity, I had the idea that a good way to optimally play the game would be to write a genetic algorithm. It was a simple: have constants for certain elements in the game that would influence what card should be chosen at each turn. My program follows the standard recipe for genetic algorithms. First, a population with randomized weights is created. For each generation, each person plays a game where all of the other players are greedy. A greedy strategy chooses the card that maximizes the number of victory points at each turn. There were only two other strategies I could think of: random and weighted, weighted being the strategy I was trying to optimize. I decided greedy would be the best strategy to train against because it the “default” way to play 7 Wonders. I also tried training my population against itself at every generation, but the results were mixed. (I think training the population against itself would possibly end up with weights being tuned to some sort of suboptimal metagame that would develop among the population.) After playing the population against a greedy strategy, each player would be assigned a fitness score based on their final number of victory points. In my algorithm, I set the fitness equal to the square of the victory points as to further bias towards better performing players. To generate the next generation, the population would breed using a roulette selection method. Also, with a small probability, mutations would give the weights a small nudge.
To actually assess whether or not the population improved, at the end, I compared the evolved population with a greedy, a random, and the first generation population of equal size. Specifically, given a pair of populations, each player would play a game with greedy opponents and the total number of victory points would be summed up for each population. I performed this 100 times for each pair to mask the effects of random chance.
Results
It doesn’t work. In fact, according to my methods of measuring improvement my genetic algorithm makes the population worse. The comparison at the end shows that the evolved population loses against the first generation with a very high probability. It also seems like the higher the number of generations the population evolves for, the higher the probability becomes. Both the evolved and first generation perform better than a greedy or random strategy. Because of this, it almost seems like the process of evolution accomplishes nothing except making things worse.
Generations: 100, Population Size: 1000
To begin my postmortem, I do acknowledge that I could have made my weights better and more specific, but based on my current results I doubt that would improve much, if at all. There are 2 things that come to mind as to why my genetic algorithm failed to work.
First is the parameter space. I came up with a set of 9 constants for each notion of value: money, military points, resources, science, etc. Additionally, I have 3 sets of these, one for each age. Basically, I have this 27 dimensional space to find some sort of combination of weights at a local maximum. Without a large enough population, it’s possible that this 27 dimensional space would not be densely packed enough to find any coherent local maximum.
The second idea that comes to mind is how big of a role randomness plays in 7 Wonders. Empirically, when I have played this game with my friends, there is little consistency with how we place among games. It’s possible we all just suck, but it’s unlikely. My theory is 7 Wonders is extremely luck based, but this aspect is hidden behind a plethora of rules and game mechanics. To support my claim, I’ll explain my thought process for developing a strategy. Let’s say I have a strategy that I want to follow throughout the game, for example, focusing on building science cards. The success of this strategy will largely depend on which cards my opponents choose from as the game progresses. If they also want to concentrate on science, then we will be competing for the same resources. Okay, that’s fine; it’s not expected that such a simple strategy would consistently perform well. I’ll modify my strategy to follow for “paths” that my opponents aren’t taking, which, in theory, would mean less competition, for the resources I seek. Given that everyone’s cards are public, I can infer what my opponents are going for by looking at their board. Now, what if the “paths” my opponents take do not work out for them, and they decide to switch plans midgame? From my experience this happens more often than not. From my experience, rarely does the distribution and cycling of cards line up perfectly with my initial plans. At this point, my current model of the game is a group of people each with their own not-necessarily-unique plan, that has a high chance of switching, possibly more than once. This is something my shoddy little genetic algorithm cannot perform well with. It seems like the largest deciding factor of success is what cards end up in your hand as the game goes on. It’s not complete chaos, but to me, it seems very close. Perhaps, a super large multilayer deep neural network that takes the entire state of the game as input and outputs a score for each card could do well.
Conclusion
I’ve decided to put this on project indefinitely on hold, maybe to be picked up again after I learn more about machine learning or artificial intelligence. The code can be found on my GitHub for anyone who does not want to go through the nightmare of coding up every mechanic of 7 Wonders.s
I recently received an email from Google notifying me that they would restrict an app I made a while back if I did not provide a privacy policy or whatever. This app, Super Smash Bros Locator, was something I made a while back, a child spawned from my love of creation and Super Smash Brothers Melee for the Nintendo Gamecube. In short, the idea was that you could find people around you on a Google Maps layout, meet up, and play smash. Anyway, I logged onto my my developer console to see what the issue was and quickly set my eyes on some heartbreaking statistics.
I took this as a sign that I should euthanize my project before something uncouth happens like Nintendo taking legal action against me or something; I don’t know. So I want to give my first ever side project a proper funeral before I put it to sleep.
I liken the life of Super Smash Bros Locator to that of the butterfly, kind of. As a caterpillar, Super Smash Bros Locator was clunky, slow, lacking elegant design, ultimately unfit to survive, but nonetheless cute. For flaws, off the top of my head, I remember handwritten SQL statements, a backend that was literally a fat if block that conditioned on a string passed in through the HTTP headers, and a irrational mix of Android activities and fragments on the frontend. However, it was a good effort. Having never touched backend before, I had something working for a single, uh I mean simple, use case.
At some point along this caterpillar’s life, development slowed down as I had implemented a good set of basic features, and my service passed my test case of logging in and randomly inputting stuff in an attempt to break something. Having confirmed this excellent robustness, I was in a “now what?” kind of state. At the time, I was also a freshman desperately trying to land a summer internship, and among my interactions with various engineers, one of them suggested that I should just release my app into the wild. Also as a desperate freshman, I took this advice as an unquestionable mandate of heaven, and so I released it. As soon as my caterpillar landed its fuzzy feet on the jungle floor (the Google Play store), it instantly combusted and was trampled by the jungle’s assortment of creatures. All sorts of bugs, unexpected features, and null pointer exceptions were reported. Despite all this, I managed to get around 2000 users in 2 days; it was exciting to a bunch of little GameCube controllers pop up all over Google Maps. I would obsessively check the number of entries within the MySQL database and naturally conclude that I was simply the best programmer to ever do it.
Seeing the large influx of users and even larger influx of bug reports, I decided to overhaul everything. I got the help of my pair programming partner, Ashwin, to rewrite the backend with Spring, Hibernate, and all those good web technologies goodies that I was not aware of. I rewrote the Android app part, adding some nice material design elements, consistent activity/fragment usage, etc. If you have been following my caterpillar analogy, this is the part where the caterpillar is chilling in the cocoon.
After a couple weeks of work, our cocoon was ready to hatch, and we re-released with the shiny new backend and an equally sleek frontend to match. Unfortunately, what we saw and what our users saw were complete opposites. We saw a sleek, 2.0, VR ready, deep TensorFlow ready, fresh butterfly, but our users saw the same unfit-to-survive caterpillar with a pair of paper-mache wings haphazardly glued onto its back.
Essentially, users saw the same clunky app the I released the first time around. Given, the polished new version did have its own share of bugs. For instance, on this release, upon revamping the backend, everyone ended up in some large public group chat when they would try and send an individual message. It was interesting to see a massive conversation between hundreds of people, but it was still unintentional.
A couple bug fixes and app updates later, here we are. A year ago, the backend would have gotten around 50 hits a day, but that has dwindled. I’ve determined that the ~10 hits I get per day is no longer worth the $15 I spend a month on maintaining the EC2 instance, and the privacy policy was the final straw. The app lost a lot of crucial momentum that it should have maintained from the first release. I feel like if everything went smoothly at the beginning, the app might have had a larger base of regular users and grown to take a spot right next to Facebook Messenger in top free apps, but somehow that didn’t happen.
In conclusion, I would say the most valuable thing I got from this experience is a taste of what it’s like to create something and have people use it. Now I know what some of you might be thinking. Wow Eric. That’s pretty dumb. I could write some dumb app, put it on the Play Store, and get users. Yeah I guess you could. I don’t really know what to say to that.